Following discussion with @misha130 last weekend, I have made changes to the pgModel to generate the initial database.
From the Round 7 discussion:
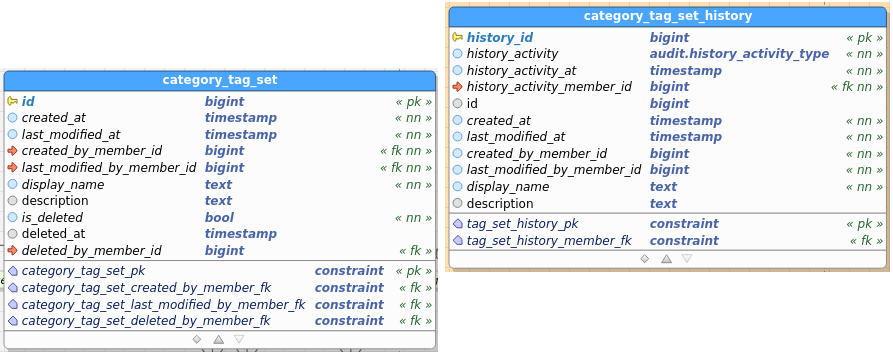
Added category_tag_set table
Changed social_media_type to external_association_type
Added ‘soft delete’ fields to all tables - I expect some (enum type) tables don’t want this, but I figured it was easier to add to everything and delete what isn’t wanted later
Added duplicate_post_id and close_reason_id to post_vote
Not from the Round 7 discussion:
Add a column “internal_id (text 50)” to enum tables (setting, privilege, post_type, vote_type)
Why can’t the dsiplay_name be used for querying (or why will internal_id remain consistent when display_name won’t). Also, with an entity framework solution there will be very little sql readable, or otherwise.
Delete the post_status table
This will be useful if we want to maintain post status history (outside of audit). If we don’t want then then it’s easy to delete and make the changes following
Following are the tables from the latest Database schema proposals.
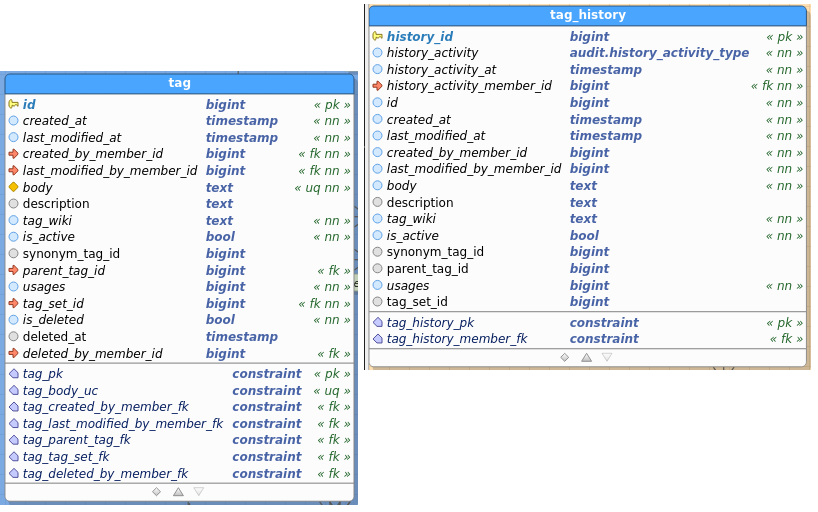
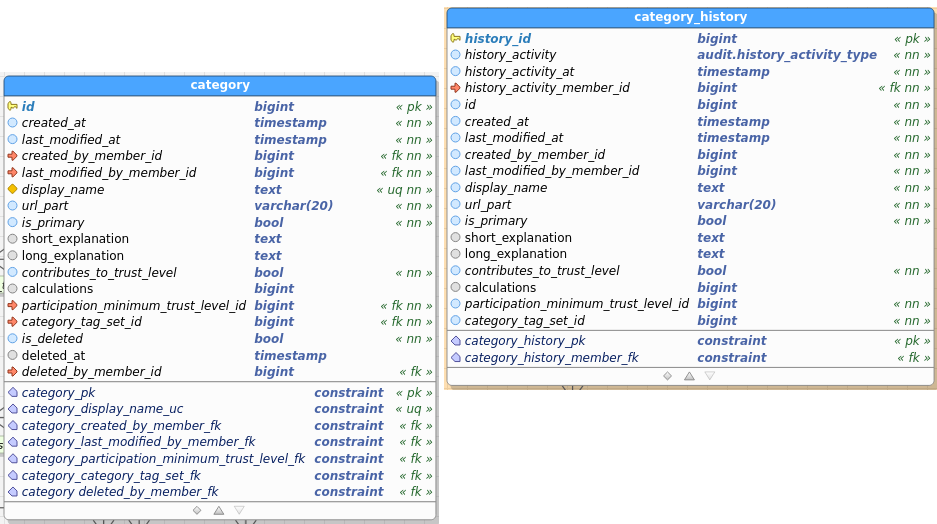
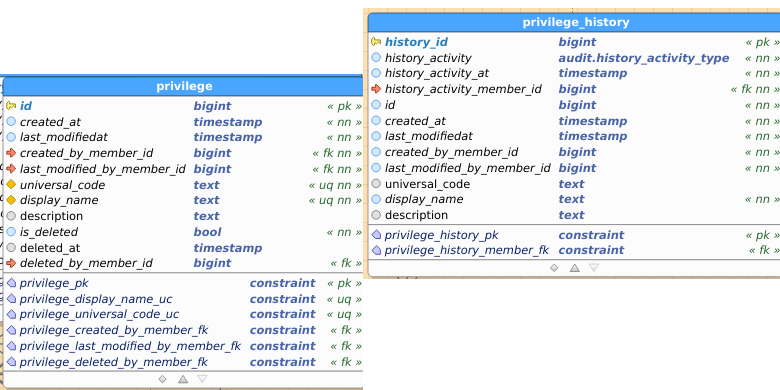
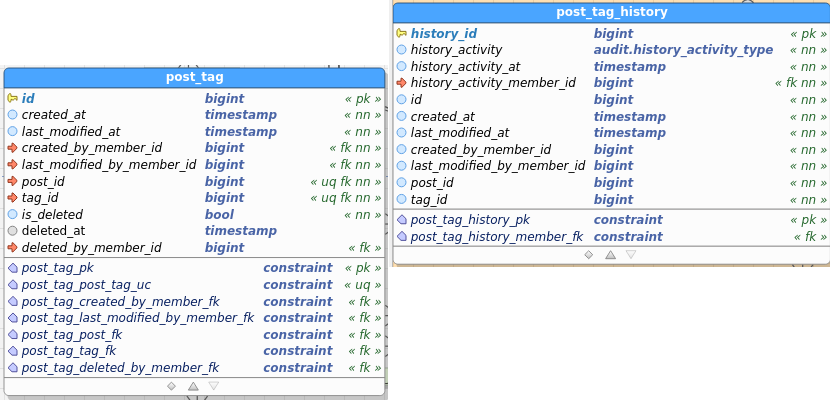
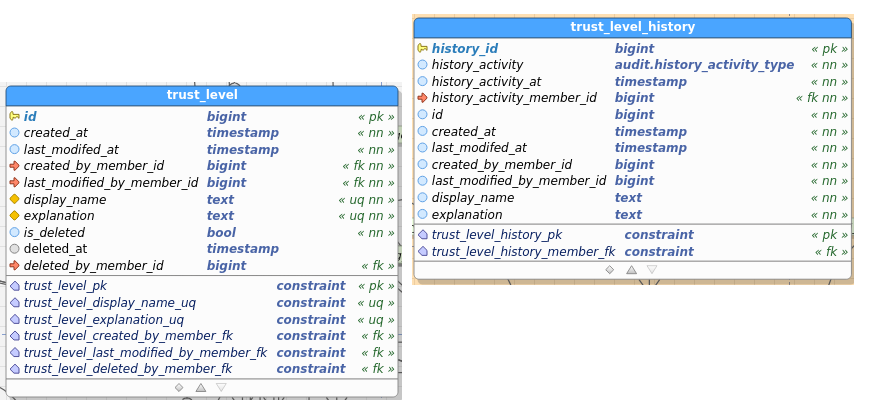
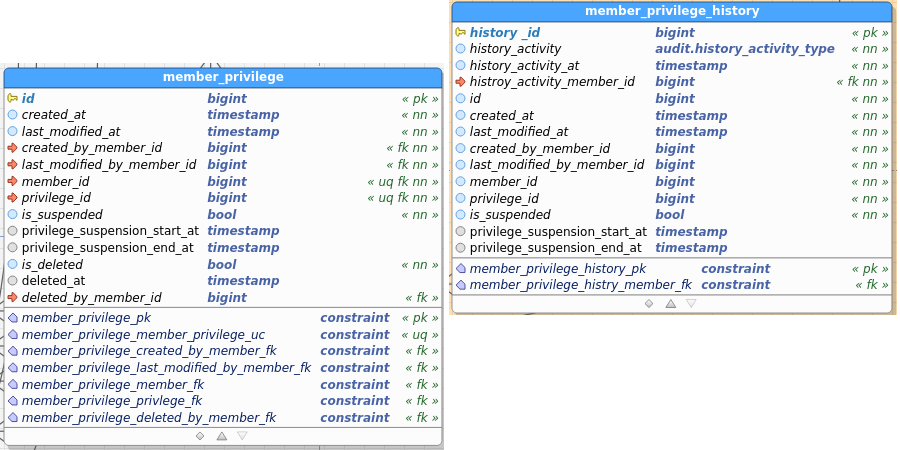
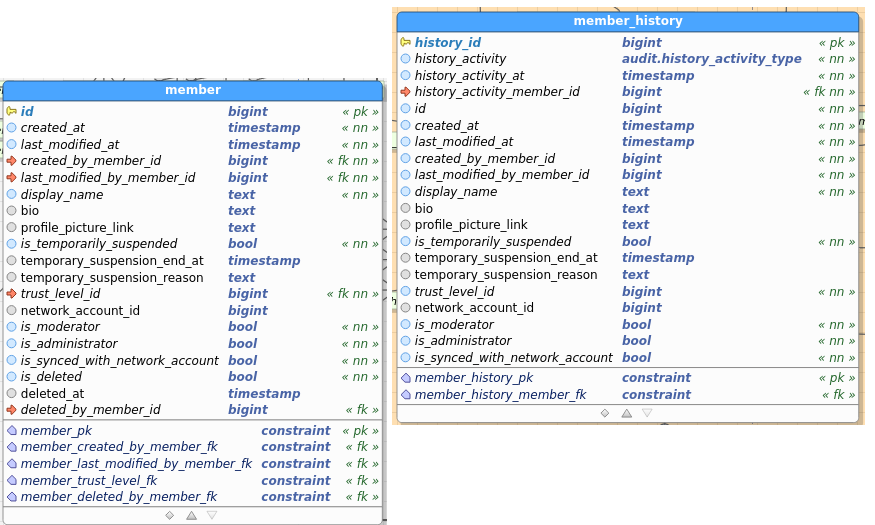
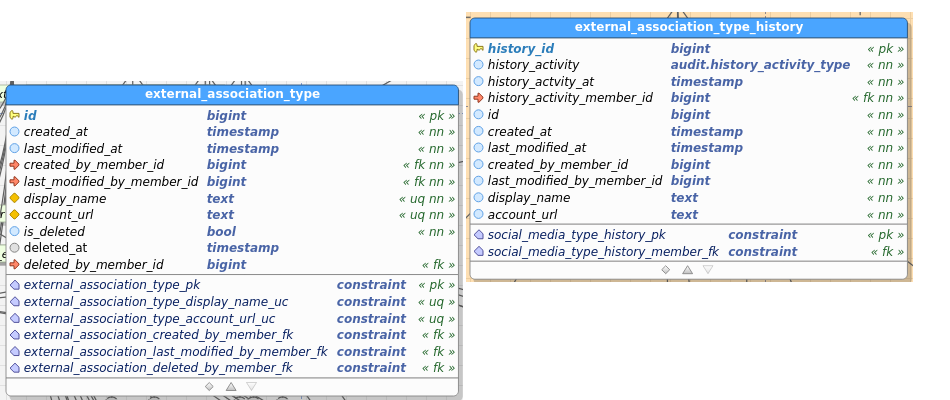
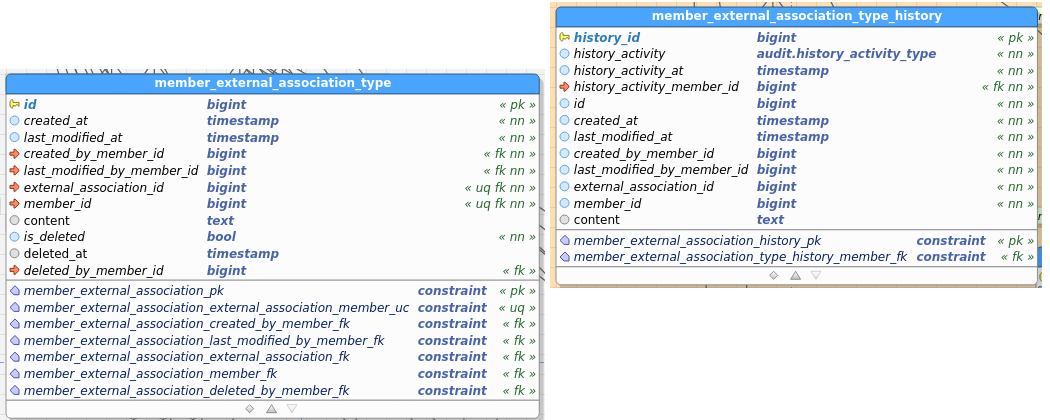
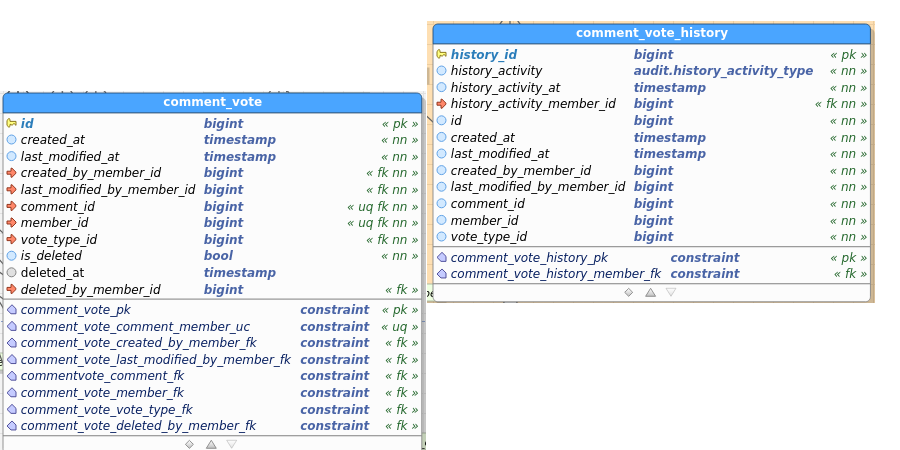
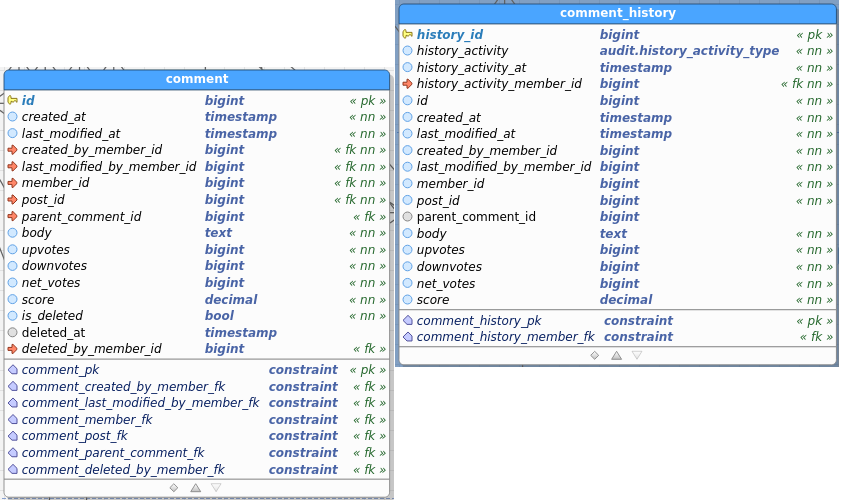
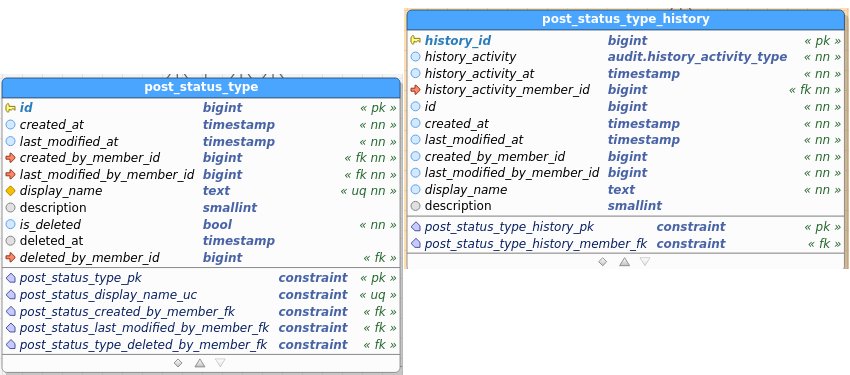
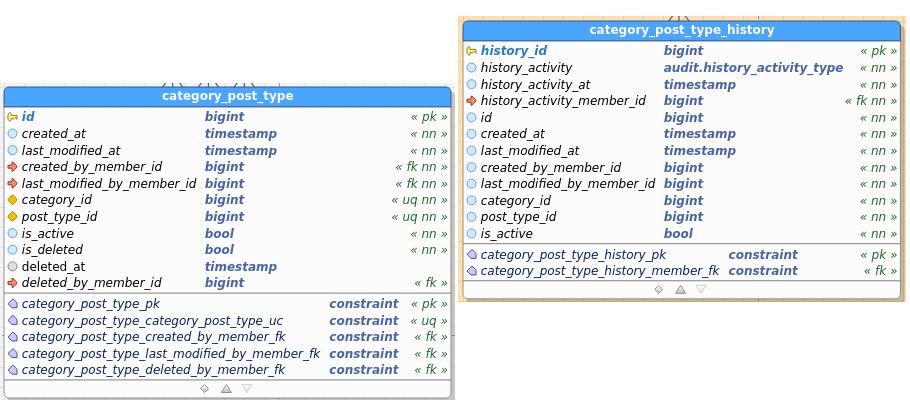
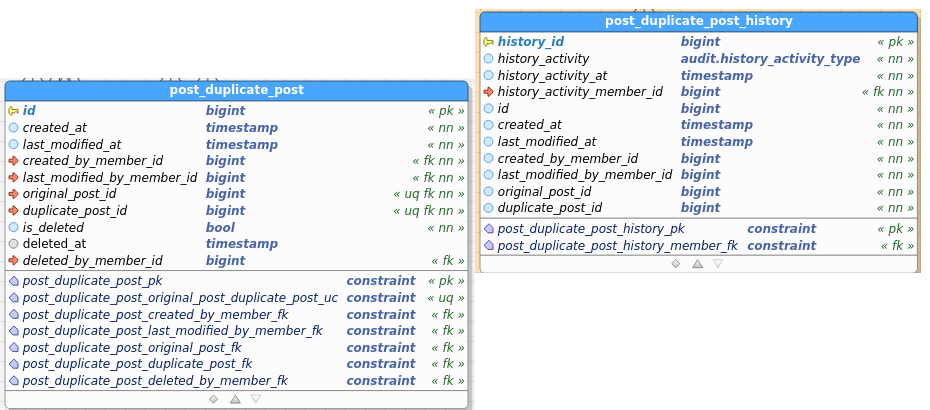
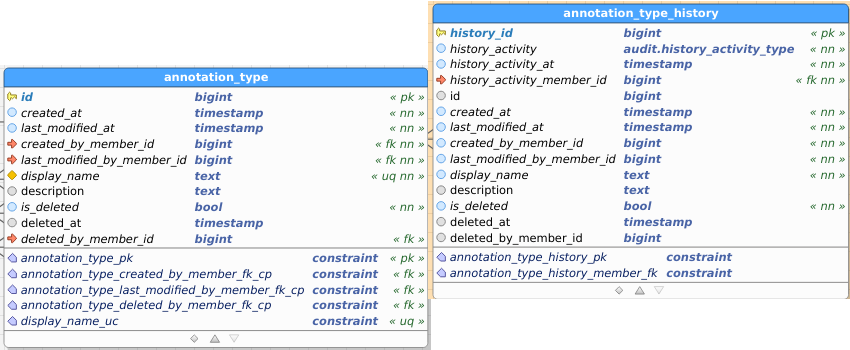
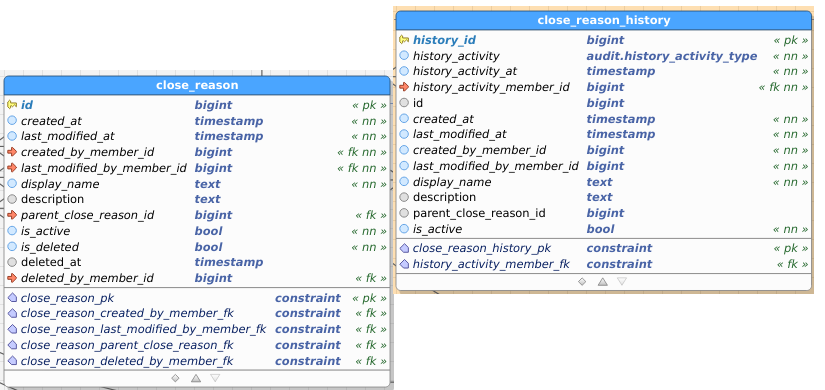
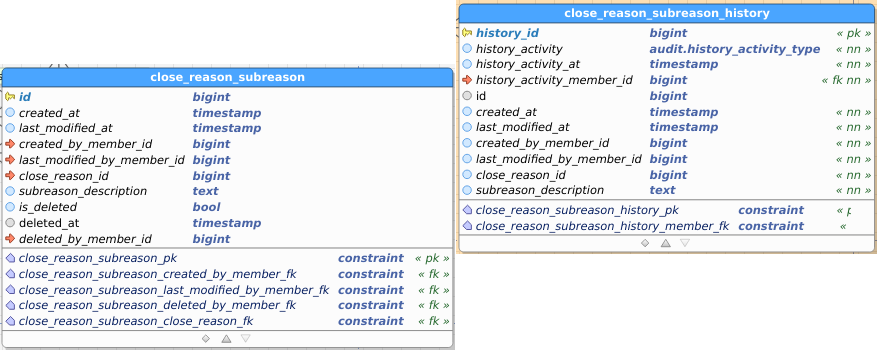
Table images below show the regular and the audit (history) table. I’ve pasted images as a) retyping all field names didn’t interest me, and b) you get to see the constraints as well and check consistency between data and audit this way.
Tag:
Category_TagSet:
Category:
Privilege:
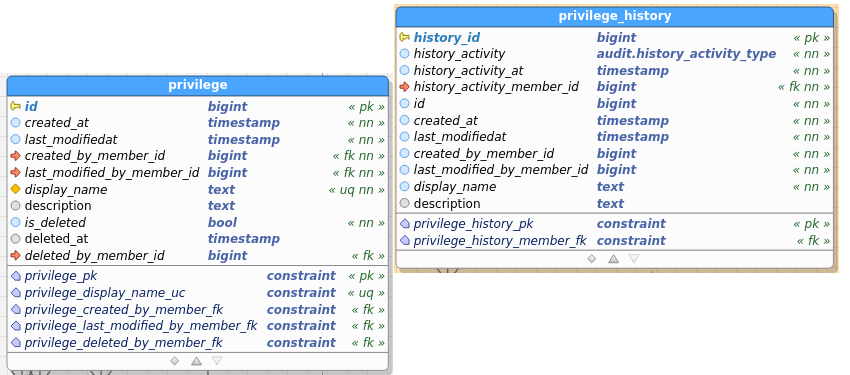
Modified Privilege:
Post_Tag:
TrustLevel:
Member_Privilege:
Post:

Modified Post:

Member:
Post_Vote:

ExternalAssociationType:
Post_Status:

Member_ExternalAssociationType:
Comment_Vote:
Vote_Type:
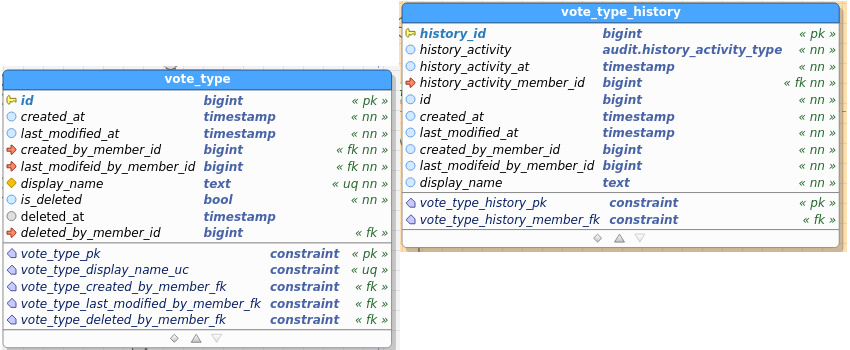
Modified Vote_Type:
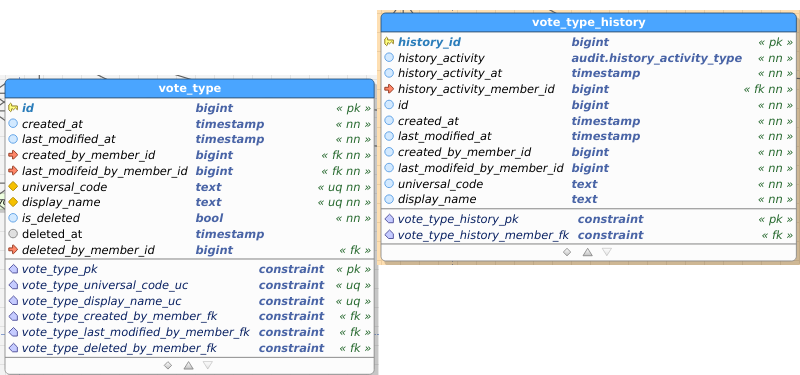
Post_Type:

Modified Post_Type:
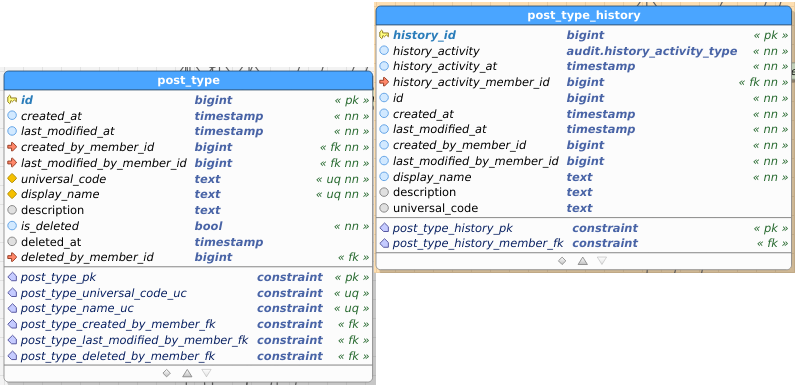
Setting:

Modified Setting:

Comment:
Post_StatusType:
Category_PostType:
Post_DuplicatePost:
New tables:
MemberAnnotation:

AnnotationType:
CloseReason:
CloseReason_Subreason:
Notice:

Outsatanding issues:
Cascade rules for ON_DELETE
Member table has a network_account_id column. We need a network_account table.
Post_Vote table has a close_reason_id column. We need a close_reason table
There are other unanswered questions in the Round 7 thread. These can be added as issues to github.
SQL file generated by pgModeler and modified version for generated (calculated) fields added to:
https://github.com/mcalexster/mcalex_codidact/tree/mcalex/skeleton/Database/Scripts/base